Today, we want to talk about 5 fundamental terms typically used by system engineers that allow you to better understand your portal’s technical functioning. You will thus be able to avoid serious problems or circumvent making the most common mistakes in the hosting sector.
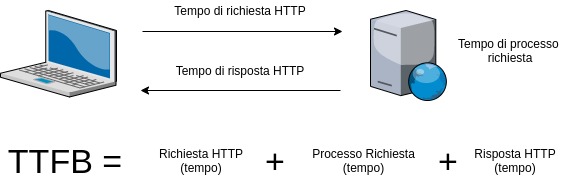
TTFB – Time To First Byte – The reception time of the first byte
It is a fundamental data point that represents a key parameter to keep an eye on.
Be careful not to confuse it with the page loading, which is influenced by the presence of plugins and by the information contained on the page, as well as by the speed of the user’s connection.
The TTFB is a parameter that indicates the speed of receiving the first byte from the server to which the user connects to the site, therefore, also the response of the portal is slightly influenced by this parameter.
How to evaluate the Time To First Byte – TTFB
0.1 – 0.2 seconds: excellent
0.3 – 0.5 seconds: good
0.6 – 0.9 seconds: average
1 – 1.5 seconds: above average
1.6 or slower seconds: very bad
A low TTFB is the mark of a well-configured web server. A very low TTFB is observed with statically served web pages (cache), while a higher TTFB is often due to numerous requests to a database.
It is one of the parameters that we provide with our performance report, it is important to take into account the starting location of the test because the network latency influences the result. We cross-use one of our farms, with different “types” of devices (PC, smartphone, tablet) and different “types” of browsers/systems (chrome, safari, explorer).
What is latency? Latency is nothing more than a measurement of the system’s response speed. It is the time interval between the moment input is sent to the system and the moment its output is available. Latency depends on “distance” and the number of network nodes between the user and the server.
Caches and their importance
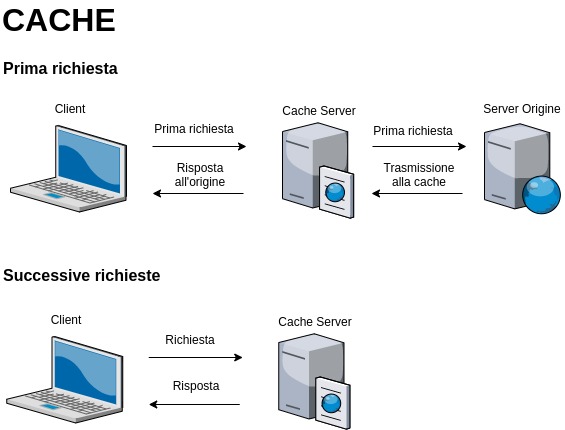
Caches have become fundamental when it comes to building an online portal. This is because these are small portions of fundamental data that are collected, obviously with the consent of the site users, to make the online browsing experience better.
This is due to the simple fact that the stored data has a very specific purpose, that is to make browsing faster since the information is used by the server to offer that particular content.
The cache data is stored on a server and therefore, during the content loading phase, the data is not requested every time that page is accessed but, on the contrary, taken directly from the server, making sure that the pages are loaded faster.
Of course, it is also necessary to arrange the various data, optimising it and making sure that it can be really useful to those who decide to use this technology, greatly improving website browsing and avoiding potential complications that make the use of the platform unpleasant.
Caching allows you to efficiently reuse data that has already been recovered or processed. All cached managed database data resides in the server’s main memory, accumulating no delay, and can use simpler algorithms to access data, using less CPU. Typically, an operation takes less than a millisecond to complete.
Redis is a memory-resident open-source key-value store with optional persistence and is installed by default on all of our dedicated cloud servers.
Cache busting solves the browser caching problem by using a unique file version identifier to tell the browser that a new version of the file is available. Therefore, the browser does not retrieve the old file from the cache but rather requests the origin server for the new file.
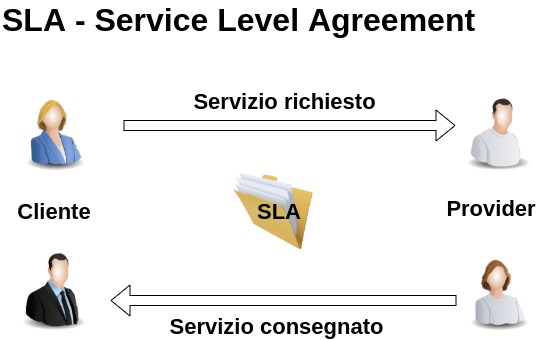
SLA – Service level agreements
In this case, we refer to actual agreements that need to be respected by the service provider, whose parameters shall be maintained throughout the contract. For example, if the provider ensures a site response speed and downloads that settle on a new level, the service provider must maintain those parameters that are described therein.
Therefore, it is necessary to keep this aspect under control, so that the end result can be optimal and able to perfectly reflect all your needs.
Consequently, if the above types of parameters are not maintained, it is possible to proceed to the request for compensation for the missing parameter.
Therefore, the choice must necessarily be carried out carefully since, otherwise, you risk not reaching the maximum degree of satisfaction and above all, you could be disappointed by the type of service that is exploited.
The definition of the SLA is based on the determination by the customer of the ideal level of service to guarantee its business.Our SLA is public and is applied to every level of product or service. It recognises to our customers a credit equal to 24 times the operational block time immediately.
A Service Level Agreement must be very clear and precisely indicate the metrics against which the service itself will be evaluated. The SLA must always indicate the compensation provided for the disservices suffered.
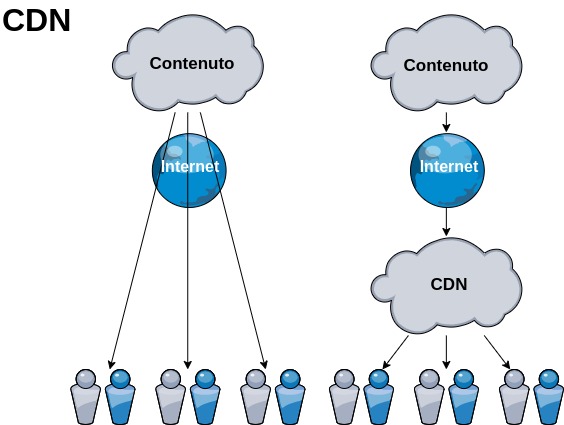
CDN – Content Delivery Network or Content Distribution Network
“Network for the delivery of content”. This is a system of computers networked through the Internet, which collaborate transparently, in the form of a distributed system, to distribute content.
CDN nodes are geographically distributed, often connected to different backbones. A centralised system with a single central server would not be able to satisfy the multiple service requests from numerous users. In other words, the Content Delivery Network (CDN) enables the delivery of data, video, applications and APIs globally to users with minimal latency, high throughput, all in a developer-friendly environment.
Optimisations derived from applying a CDN can lead to cost savings for bandwidth, or improved performance, or both. For example, we provide a solution that uses one of our datacentres as the main data hosting, one of our directly connected datacenters for the management of backups and disaster recovery and finally a CloudFlare CDN for the distribution of static data.
The term node in internet networks generically indicates a processing transceiver device that can be positioned at the edges of the network itself, a terminal node (host) or inside it as a transit node or switching between various output lines, for example in the transport network.
Load Balancing
This is the sharing of the information processing load.
This allows the site to be faster and guarantee a more precise response every time an action is taken by a visitor, such as a request for a service or the use of a page.
To improve scalability, that is the division of the site’s workload, it is necessary to create several clusters and exploit various servers, which must communicate with each other and be carefully monitored.
This is fundamental because, if a server should be subject to problems, another containing the same information immediately takes over, thus allowing the visitor to take advantage of different types of data or services.
For example, if 15 clusters are used, the different questions are divided among them: this allows for rapid responses.
Creating copies of clusters and placing them on the various servers that are used allows you to maintain the reliability of the site at the highest levels, thus preventing any potential problems.
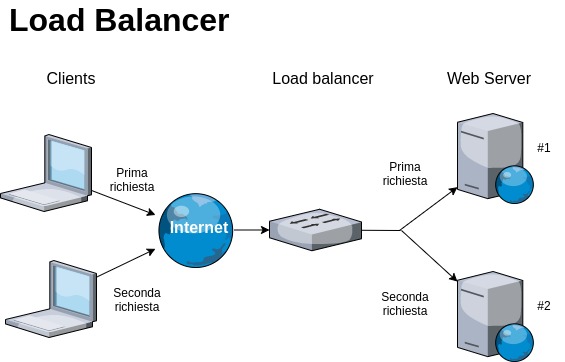
Load balancing systems generally integrate monitoring systems that automatically exclude unreachable servers from the cluster and thus avoid making a portion of user service requests fail.
Our systems exploit full high availability (HA) architecture , i.e. the load balancing system is also made up of a cluster in HA.
IOPS (input/output operations per second) – crucial in cloud hosting!
RAM with its high IOPS (I/O operations per second) handling capabilities is the preferred medium for memory caching engines, data retrieval performance is better and large scale costs are reduced.







